剖析go二进制文件
Posted 2020-09-06 18:55 +0800 by ZhangJie ‐ 3 min read
为什么要反汇编?
这篇文章介绍下反汇编的基本概念,以及如何用go语言写一个简单的反汇编器。本文的目标就是为了尽可能描述下反汇编的的相关概念,以及让读者朋友们了解go二进制程序内部大致是什么样的。
汇编代码不会撒谎,阅读汇编代码能够让我们更细致地了解处理器执行的指令到底做了什么。这也是为什么反汇编很重要的原因之一。如果我们有一个二进制程序,并且怀疑它有一些恶意的行为,通过反汇编来研究它就是一种很好的途径。再或者,如果你分析代码难以发现性能瓶颈,那么反汇编也是一种可以简化分析的途径。
如果你担心能不能阅读x86_64汇编代码的问题,其实不用担心,我们大部分都不能很顺畅地阅读。你也没有必要为了搞懂这篇文章去阅读其他任何的汇编代码,不过如果有汇编基础的话确实会感觉更有意思点。这里有一篇介绍汇编基础的文章 A fundamental introduction to x86 assembly programming。
什么是反汇编?
那么,什么是反汇编呢?
反汇编,其实是将已经编译好的二进制程序,重新转换为汇编代码的过程。为了解释清楚,我们先考虑下从源代码编译构建的过程:
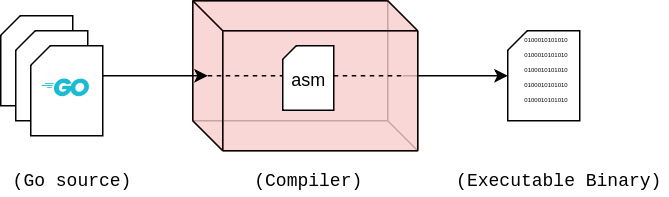
汇编代码,其实是一种介于源代码、机器指令之间的中间代码表示,虽然大多数汇编指令是和机器指令对应的,但是也不绝对,比如go汇编就是一种跟机器指令没有明显对应关系的汇编形式。详细地可以参考go assembler设计对应的go blog一文。ok,言归正传。编译器首先将源代码转换为OS/架构特定的汇编代码,然后再通过汇编器将汇编代码转换为机器指令。从字面上就可以看出disassemble是assemble的一个逆向的过程,俗称反汇编。
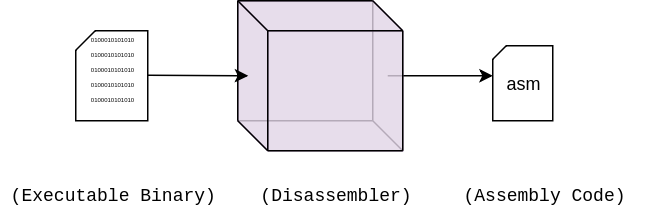
庆幸地是,go语言有一个相对标准、完整的工具链,汇编、反汇编都会比较方便。我们可以直接将源码转换成汇编代码来查看,例如通过运行命令 go build -gcflags -S program.go。如果我们已经有了一个编译构建好的二进制程序,这个时候想查看汇编代码的话,就得通过反汇编,可以运行命令 go tool objdump binaryFile。
如果想了解如何实现汇编、反汇编的话,这篇文章其实已经可以结束了。但是如果来解释下如何从0到1构建一个反汇编器的话,还是有意思的。
从0到1构建反汇编器?
首先,为了构建一个反汇编器,我们需要先知道二进制程序对应的目标机器架构包含的所有的机器指令。为了实现这个,我们可能要参考特定架构的手册来查阅到底有多少机器指令。如果对这个不熟悉,这个过程其实是比较困难的。其实,有很多种微处理器架构、汇编语法、指令集、编码模式,而且一直在变。光掌握这些不同机器架构包含的指令集就是一个很困难的事情,至于如何困难可以参考下这篇文章 how many x86_64 instructions are there anyway。
{kind=link}
庆幸地是,这些繁重的工作应被解决了,反汇编框架Capstone就是干这个事情的。Capstone其实已经是一个事实上的标准了,在各种反汇编工具中应用广泛。重新实现一个反汇编框架,其实没必要,这个过程只会是一个学习性的、枯燥的、重复的任务,我们不会介绍如何实现一个Capstone反汇编框架,只会介绍如何借助Capstone来实现反汇编的能力。在go语言中使用Capstone也简单,有一个针对go的实现gapstone。
通过下面的代码我们可以初始化一个gapstone反汇编框架引擎,用它来执行后续的反汇编任务。
engine, err := gapstone.New(
gapstone.CS_ARCH_X86,
gapstone.CS_MODE_64,
)
if err != nil {
log.Fatal(err)
}
例如,我们可以将下面的原始指令数据传递给Capstone反汇编框架,然后该反汇编框架将会将这些原始指令数据转换为对应的x86_64下的指令。
0x64 0x48 0x8B 0xC 0x25 0xF8 0xFF 0xFF 0xFF
|
mov rcx, qword ptr fs:[0xfffffffffffffff8]
把上面的操作放在一起,如下:
file: main.go
input := []byte{0x64, 0x48, 0x8B, 0xC, 0x25, 0xF8, 0xFF, 0xFF, 0xFF}
instructions, err := engine.Disasm(input, 0, 0)
if err != nil {
log.Fatal(err)
}
for _, instruction := range instructions {
fmt.Printf("0x%x:\t%s\t\t%s\n", instruction.Address, instruction.Mnemonic, instruction.OpStr)
}
测试下:
$ go run main.go
0x0: mov rcx, qword ptr fs:[0xfffffffffffffff8]
有了这个反汇编框架Capstone之后,要实现一个反汇编器,我们还有一个剩下的工作要做,就是从二进制程序中提取指令对应的原始数据,然后将其传给Capstone翻译引擎就可以了。
当你在一个笔记本上编译一个go程序、默认输出是64位ELF格式(Executable Linkable Format)。ELF内部其实是被组织成了多个不同的节(section),每一个section都有不同的目的,如存储版本信息、程序元数据信息、可执行代码等等。ELF是被广泛采用的一个二进制程序标准,go语言标准库里面提供了一个 debug/elf package用来进行ELF文件数据的读写。ELF其实有点复杂,但是要实现反汇编的话其实我们只关心两个section就可以了。一个是符号表section(.symtab),一个是指令section (.text)。
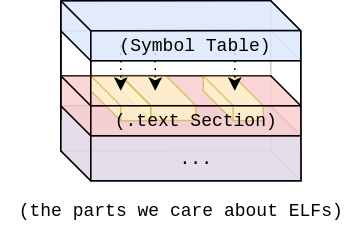
首先,我们先来看下术语symbol的定义,其实它指的是代码中任何有名的东西,如变量、函数、类型、常量等都是symbols。go编译器会编译每一个符号,并存储对符号表中符号的引用信息。go标准库 debug/elf 中提供了对ELF文件的读写能力,每一个符号都通过结构体 Symbol 来表示,它包括了符号的名字、地址、原始数据的多少等等吧。
// A Symbol represents an entry in an ELF symbol table section.
type Symbol struct {
Name string
Info byte
Other byte
Section SectionIndex
Value uint64
Size uint64
}
现在,如果我们想快速提取ELF文件中的所有符号的话,我们就可以这么实现:
// Open the ELF file
elfFile, err := elf.Open(path)
if err != nil {
log.Fatalf("error while opening ELF file %s: %+s", path, err.Error())
}
// Extract the symbol table
symbolTable, err := elfFile.Symbols()
if err != nil {
log.Fatalf("could not extract symbol table: %s", err.Error())
}
// Traverse through each symbol in the symbol table
for _, symbol := range symbolTable {
/*
symbol.Info lets us tell if this symbol is a function that we want to disassemble
symbol.Value gives us the offset from the start of the .text section
symbol.Size lets us calculate the full address range of this symbol in the .text section
*/
}
从Symbol各个字段的名字命名上看并不是很清晰,符号对应的内存偏移量其实是存储在Value字段中的。通过这个偏移量,可以通过计算与.text section的偏移量的差值,我们可以计算出符号对应的指令数据在.text section中的起始索引。通过进一步的Size我们可以计算出包含的指令数据对应的字节数量。还有一个就是Info字段,这个字段起始是类型的意思,在go里面Info=byte(2)表示的是函数,Info=byte(18)表示的是方法。所以,如果想实现对函数、方法的反汇编的话,我们只处理这两种类型的就可以了。
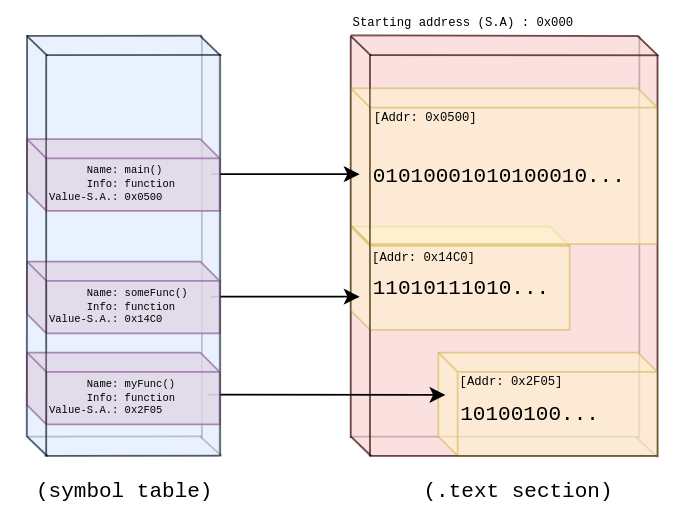
有了这些之后,我们就可以快速的再完善一下了:
// extract the .text section
textSection := elfFile.Section(".text")
if textSection == nil {
log.Fatal("No text section")
}
// extract the raw bytes from the .text section
textSectionData, err := textSection.Data()
if err != nil {
log.Fatal(err)
}
// traverse through the symbol table
for _, symbol := range symbolTable {
// skip over any symbols that aren't functinons/methods
if symbol.Info != byte(2) && symbol.Info != byte(18) {
continue
}
// skip over empty symbols
if symbol.Size == 0 {
continue
}
// calculate starting and ending index of the symbol within the text section
symbolStartingIndex := symbol.Value - textSection.Addr
symbolEndingIndex := symbolStartingIndex + symbol.Size
// collect the bytes of the symbol
symbolBytes := textSectionData[symbolStartingIndex:symbolEndingIndex]
// disasemble the symbol
instructions, err := engine.Disasm(symbolBytes, symbol.Value, 0)
if err != nil {
log.Fatalf("could not disasemble symbol: %s", err)
}
// print out each instruction that's part of this symbol
fmt.Printf("\n\nSYMBOL %s\n", symbol.Name)
for _, ins := range instructions {
fmt.Printf("0x%x:\t%s\t\t%s\n", ins.Address, ins.Mnemonic, ins.OpStr)
}
}
完整的实例代码,详见 full disassembler。实现一个简单的反汇编器,实际上只用了70~80行代码而已。下面是一个简单的运行实例。

注意: 在测试的时候,需要注意下capstone的版本、gapstaone的版本,不然测试的时候可能会出错。这里先暂时不详细写了,遇到问题可以去repo下查issue。
参考内容
1.dissecting go binaries, https://www.grant.pizza/dissecting-go-binaries